Data Collection
To train RefVNLI, we collect a large scale dataset of < Imageref , prompt , Imagetgt > triplets, each with two binary labels: one for subject preservation of Imageref in Imagetgt , and one for textual alignment between the prompt and Imagetgt . This involves first creating subject-driven { Imageref , Imagetgt } pairs, followed by automatic generation of subject-focused prompts for each Imagetgt .
1. Subject-drive Image-pairs:
Robustness to Identity-agnostic Changes
To ensure our { Imageref , Imagetgt } dataset is robust to identity-agnostic changes (e.g., pose, clothing, or lighting changes), we use video-based datasets that inherently capture these differences.
Specifically, given two pairs of frames, each extracted from distinct video scenes featuring the same entity (e.g.,a dog), where both frames within each pair depict the same subject (e.g., the same dog), we curate training { Imageref , Imagetgt } pairs for subject preservation classification.
Positive pairs are formed by pairing a cropped subject from one frame (e.g., dog from left frame in Scene 1) with the full frame from the same scene (right frame in Scene 1). In contrast, negative pairs are created by pairing the cropped subject with the other scene's full frames (e.g., Scene 2).
This process is applied to all four frames, with each taking turns as the cropped reference image ( Imageref ), while the corresponding full-frame counterparts serve as Imagetgt , yielding a total of 4 positive and 8 negative training pairs.
In total, we collected 338,551 image pairs from 44,418 unique frames.

2. Subject-drive Image-pairs:
Sensitivity to Identity-specific Attributes
To further enhance sensitivity to identity-specific attributes, such as facial features in humans or shapes and patterns in objects, we apply fine-grained corruptions on identity-defining visual attributes for additional hard-negatives.
Starting with an image and a mask of a subject (e.g., a bag), we randomly keep 5 patches within the masked area ([1]) and use them to create 5 inpainted versions ([2]).
The version with the highest MSE between the altered and original areas (e.g., bottom image, MSE = 3983) is paired with the unmodified crop to form a negative pair, while the original image and the same crop create a positive pair, with the crop acting as Imageref in both cases.
This process yields extra 16,572 pairs.

3. Image-prompt Pairs
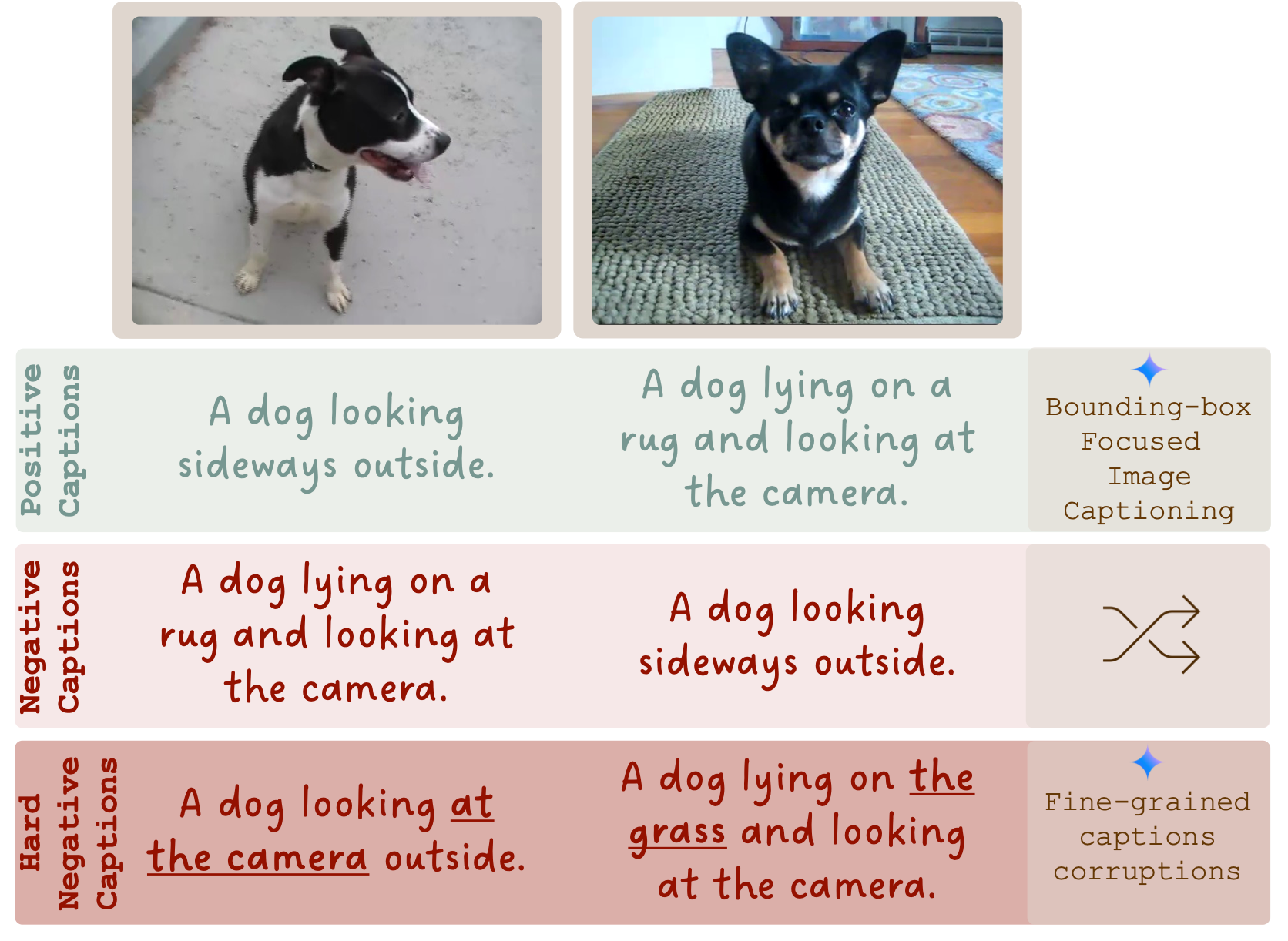
For each { Imageref , Imagetgt } pair, we generate positive and negative prompts for Imagetgt .
Specifically, given an image with some subject (e.g., a dog), we create a positive prompt by adding a bounding box around the subject and directing an LLM to describe it (top prompts). Negative prompts are created by swapping prompts between images of the same entity (middle prompts). For additional hard negatives, we guide an LLM to modify a single non-subject detail in the positive prompts while keeping the rest unchanged (bottom prompts).
In total, combining this step with the two image-pairing steps yields 1.2 million < Imageref , prompt , Imagetgt > triplets labeled for textual alignment and subject preservation.